The Search Platforms Survey
An honest survey of the major platforms: Elasticsearch/OpenSearch, Solr, Vespa, Algolia, Coveo, vector DBs, cloud search.
About This Catalog
This is Volume 8 of the Search Engineering Series, the final planned volume. The series has thus far covered the technical disciplines (Volumes 1–5), the operational practice (Volume 6), and the user-facing surfaces (Volume 7). This volume surveys the platforms on which all of that work runs — Elasticsearch, OpenSearch, Solr, Vespa, Algolia, Coveo, the vector databases, and the cloud-provider search offerings. The volume is structurally different from the prior seven: rather than cataloguing patterns, it compares platforms across the dimensions established by the prior volumes.
The volume's perspective. Platform comparisons in the search space are often promotional rather than analytical. Vendor blogs argue that their platform is best; consultants with platform specialties recommend their platform; community discussions are dominated by users of one platform speaking favorably about it. The honest comparison — acknowledging real strengths and limits without bias toward any particular platform — is harder to find. This volume aims for that comparison. The author has worked with multiple platforms (Coveo for enterprise clients, Elasticsearch and OpenSearch in general practice, exposure to Solr and Algolia in specific engagements) and tries to apply each lens honestly. No platform wins on every dimension; the question is which dimensions matter most for the specific workload.
Why this volume comes last. The first seven volumes documented what to do; this volume documents what to do it with. Reading the prior volumes first establishes the vocabulary needed to compare platforms meaningfully. "Elasticsearch has good vector support" means nothing without the Volume 4 vocabulary about what vector support involves; "Solr has thinner LTR tooling than Elasticsearch" means nothing without Volume 4's framing of learning-to-rank. The platform survey assumes the discipline framing the prior volumes provide; it's the application of that framing to specific products.
Currency caveat. Platform capabilities change rapidly. Features documented here as present-or-absent in early 2026 may shift by the time the reader applies this material. The volume tries to focus on each platform's structural strengths and limits — the things that have been stable for years and are likely to remain so — rather than feature-by-feature comparisons that age quickly. For current detail, the practitioner should verify against each platform's current documentation and recent release notes.
Scope
Coverage:
- The major general-purpose search platforms: Elasticsearch, OpenSearch, Apache Solr, Vespa.
- The major commercial / SaaS platforms: Algolia, Coveo, plus the cloud-provider offerings (Microsoft AzureAI Search, Google Vertex AI Search, Amazon Kendra).
- The vector-specialized platforms: Pinecone, Weaviate, Qdrant, Milvus, Chroma, plus relational-database vector extensions (pgvector, etc.).
- The dev-first specialized platforms: Typesense, MeiliSearch.
- Comparison framing: the dimensions of platform comparison; the decision tree for platform fit; vector integration patterns; migration considerations.
Out of scope:
- Older or niche platforms with limited current adoption (Sphinx, Xapian, Whoosh, etc.). Mentioned briefly where relevant; not surveyed in depth.
- Domain-specialized platforms (legal search, scientific search, code search engines) with their own conventions.
- Generic database full-text search (MySQL, MongoDB, etc. beyond Postgres) where the search capability is incidental to the database's primary role.
- Vector embedding model providers (OpenAI, Cohere, Voyage AI, etc.) — these are inputs to search platforms, not platforms themselves. Volume 4 covers their use.
- LLM orchestration frameworks (LangChain, LlamaIndex) — these sit above search platforms; covered in the agentic AI series.
How to read this catalog
Part 1 ("The Narratives") is conceptual orientation: what a platform survey is and the limits of platform comparison; the landscape of platforms and how they categorize; the dimensions of comparison; choosing and migrating; the multi-platform reality of modern search stacks. Five diagrams sit in Part 1.
Part 2 ("The Substrates") is the platform reference, organized by section. Each section opens with a short essay on what its platforms share. Each platform appears as a structured entry: what it is, strengths, limits, best fit, operational notes.
Part 1 — The Narratives
Five short essays orient the reader to the platform survey discipline. The platform entries in Part 2 assume the framing established here.
Chapter 1. What a Platform Survey Is
A platform survey is comparison material for practitioners making platform decisions. It's structurally different from a pattern catalog (which is prescriptive about technique) and from a vendor evaluation (which is bound to a specific RFP). The survey lays out the platform landscape, identifies the dimensions on which platforms differ, and offers framings that help readers map their own workload to platform candidates. The discipline is honest comparison without promotional bias toward any specific platform.
Why platform comparison is hard. Platforms are complex artifacts with many capabilities; meaningful comparison requires understanding each platform's capabilities along many dimensions, and few practitioners have deep experience across multiple platforms. The available comparison material is dominated by: vendor marketing (biased toward whoever produced it); community discussion (biased toward users of specific platforms); consulting recommendations (biased by the consultant's specialty). Honest comparison requires sources of evidence that cut across these biases — production case studies from teams using multiple platforms, technical benchmarks done with care, and the discipline of acknowledging what one doesn't know.
The limits of platform comparison. No comparison applies universally. A platform that fits one team poorly may fit another well. The dimensions that matter for one workload may not matter for another. The team's existing skill, infrastructure, and organizational context affect platform fit substantially — often more than the platform's capabilities themselves. The discipline is offering comparison framings that help readers identify the dimensions that matter for them, not delivering verdicts.
What this volume is and isn't. It is: a comparison framing across major platforms; structured per-platform entries identifying strengths, limits, and best-fit workloads; a decision tree for narrowing platform choices; migration considerations for teams contemplating platform changes. It is not: a feature-by-feature benchmark (those age quickly and depend on workload specifics); a recommendation for a specific platform (that depends on the team and context); a substitute for hands-on evaluation (no platform decision should rest only on third-party comparison).
The author's position. The author has worked with multiple platforms across various engagements: Coveo for enterprise e-commerce clients (Bass Pro Shops and similar workloads); Elasticsearch and OpenSearch across various general engagements; Solr in earlier work; AzureAI Search in specific Microsoft-stack engagements; vector databases in evaluation work. The volume reflects this multi-platform exposure rather than deep specialization in any one. Specialists in any single platform will have deeper detail than this volume provides; the value-add here is the cross-platform framing that specialists rarely produce.
Chapter 2. The Platform Landscape
The search platform landscape has expanded substantially over the last decade. Where Elasticsearch and Solr were once the dominant choices for non-trivial production search, the landscape now includes specialized vector databases, cloud-provider managed offerings, dev-first lightweight platforms, and AI-positioned commercial platforms. The diversity is genuine — different platforms genuinely serve different needs — not just market crowding.
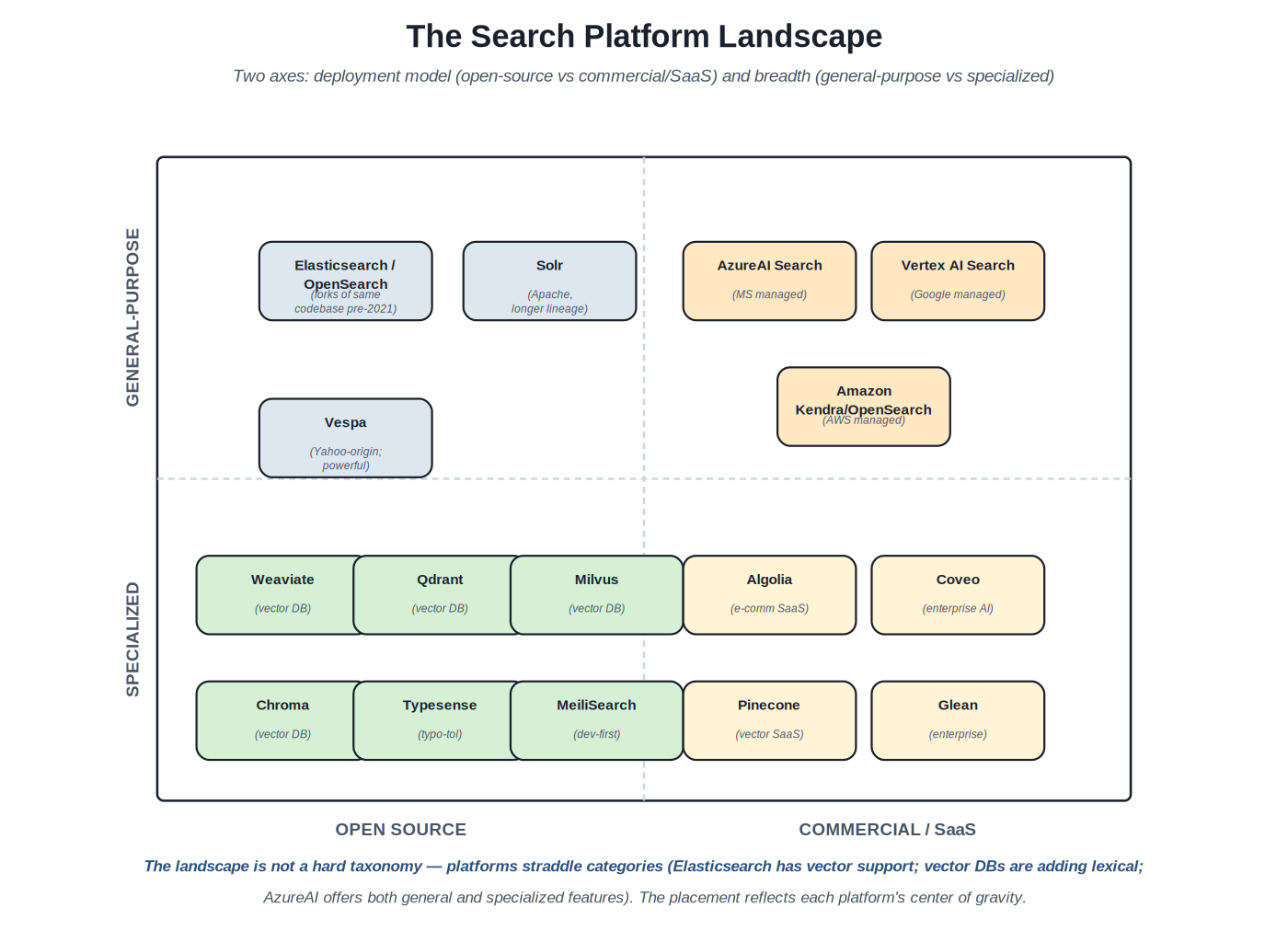
{kind=link}
Two axes: open-source vs commercial/SaaS, and general-purpose vs specialized. Platforms straddle categories; placement reflects each platform's center of gravity.
The categories. The two-axis framing is useful but imperfect. The open-source vs commercial axis tracks deployment model and licensing; open-source platforms (Elasticsearch through 7.x, OpenSearch, Solr, Vespa, the open-source vector DBs) can be self-hosted or used via managed services from vendors; commercial / SaaS platforms (Algolia, Coveo, Pinecone, the cloud-provider offerings) are primarily consumed as services. The general-purpose vs specialized axis tracks scope; general-purpose platforms handle a broad range of search workloads (lexical, vector, faceted, aggregations); specialized platforms focus on specific aspects (vector-only, typo-tolerance-focused, e-commerce-specific). Platforms straddle these categories — Elasticsearch has substantial vector support and could appear in multiple quadrants — but the placement reflects each platform's center of gravity.
The history matters. The platforms didn't emerge in parallel. Solr (2004) and Elasticsearch (2010) emerged as Lucene-based open-source search engines for general-purpose workloads. Vespa was Yahoo's internal search platform, open-sourced in 2017. Algolia (founded 2012) emerged as the SaaS alternative for e-commerce and content search where ops were a burden. Vector databases (Pinecone 2019, Weaviate 2019, Qdrant 2020, Milvus 2019, Chroma 2022) emerged with the wave of embedding-based search through 2022–2024. The OpenSearch fork (2021) followed the Elasticsearch license change. The cloud-provider offerings (AzureAI Search, Vertex AI Search, Kendra) emerged as cloud providers consolidated their offerings. The landscape today reflects this history; understanding why each platform exists illuminates what it's good for.
The crowding. The current landscape is crowded — dozens of viable platforms across the categories. Some of this crowding will consolidate; many of the vector-DB-only platforms will either be acquired, become differentiated specialists, or fade as general-purpose platforms absorb their capabilities. The trend through 2024–2026 has been unification — Elasticsearch, OpenSearch, Solr, and others have all added meaningful vector support, reducing the need for separate vector DBs in many cases. The trend toward unification is likely to continue; teams adopting platforms today should plan for the possibility that the current landscape consolidates over the next few years.
The cross-category patterns. Some patterns cross the landscape. Most modern platforms support some form of hybrid lexical+vector search (Pattern A in the integration diagrams below). Most support some form of synonym handling and query expansion. Most support faceted aggregations. The platforms differ in how mature, performant, and well-tooled each capability is, not in whether they exist. The differentiation is increasingly in operational characteristics (cost, ease of use, ecosystem) rather than in fundamental capability gaps.
Chapter 3. Comparing Platforms
Platform comparison requires structured dimensions. Comparing on "which is better" is meaningless without specifying for what. The disciplines from the prior seven volumes provide the dimensions: architectural capabilities (Volume 1), query understanding support (Volume 2), indexing and schema flexibility (Volume 3), ranking and ML support (Volume 4), evaluation tooling (Volume 5), operations and observability (Volume 6), UX integration (Volume 7), plus cost/licensing and ecosystem dimensions that span all of them.

{kind=link}
Each platform should be evaluated across the disciplines from Vols 1–7 plus cost/licensing and ecosystem dimensions. No single platform wins on every dimension.
The dimensions explained. Architecture and scale (Volume 1) tracks the sharding model, replication, cluster topology, multi-region capability — the structural properties that determine whether a platform can handle the workload's scale. Query understanding (Volume 2) tracks analyzer chains, built-in NLP support, multilingual support, LLM integration capability. Indexing and schema (Volume 3) tracks schema flexibility, analyzer plugins, reindex tooling, CDC integration. Ranking and ML (Volume 4) tracks BM25 implementation quality, LTR support depth, native vector search, reranker integration. Evaluation tooling (Volume 5) tracks built-in judgment workflows, A/B testing primitives, metric dashboards. Operations and observability (Volume 6) tracks monitoring, alerting, tracing, query log access. UX and component libraries (Volume 7) tracks out-of-box UI components, autocomplete tooling, faceting helpers. Cost and licensing tracks per-doc/per-query pricing, managed vs self-host TCO. Ecosystem and talent tracks engineer availability, community size, commercial support.
Weighting the dimensions. Different workloads weight these dimensions differently. A team with hundreds of millions of documents and complex aggregations weights architecture and scale heavily. A team in a regulated environment weights operations and observability heavily (they need audit trails, retention controls, access logs). A team with limited engineering capacity weights cost (specifically operational complexity cost) heavily. A team building a fresh e-commerce product weights UX and component libraries heavily. The discipline is identifying which dimensions matter most for the workload before evaluating platforms.
Comparison failure modes. Common ways platform comparison goes wrong. Featuritis: comparing platforms by counting features, regardless of which features actually matter for the workload. Brand-led comparison: deferring to platforms with strong marketing rather than evaluating systematically. Specialty bias: a consultant or engineer with platform-specific expertise will see their platform as better than it is. Benchmark fixation: focusing on isolated performance benchmarks that don't reflect the workload's real demands. Status-quo bias in the wrong direction: assuming the current platform must be replaced rather than evaluating fairly. The discipline is recognizing these failure modes and structuring comparison to avoid them.
Sources of evidence. Where to look for honest comparison information. Per-platform documentation — each platform's docs describe its capabilities (in flattering terms but with technical detail). Production case studies — teams that have used multiple platforms write about their comparative experience (rarer than vendor-led case studies but more valuable). Benchmark studies — academic and industry benchmarks comparing platforms on specific workloads (look for benchmarks not produced by any platform vendor). The author's own experience — hands-on prototyping with candidate platforms is the most informative single activity for platform decisions. The combination of these sources produces a defensible view.
Chapter 4. Choosing and Migrating
Two distinct decisions: choosing a platform for a new build, and migrating from an existing platform. The two decisions look similar superficially but have different dynamics. The new-build decision optimizes for fit with the workload and team. The migration decision must additionally justify the migration cost and risk relative to the status-quo platform's continued use.
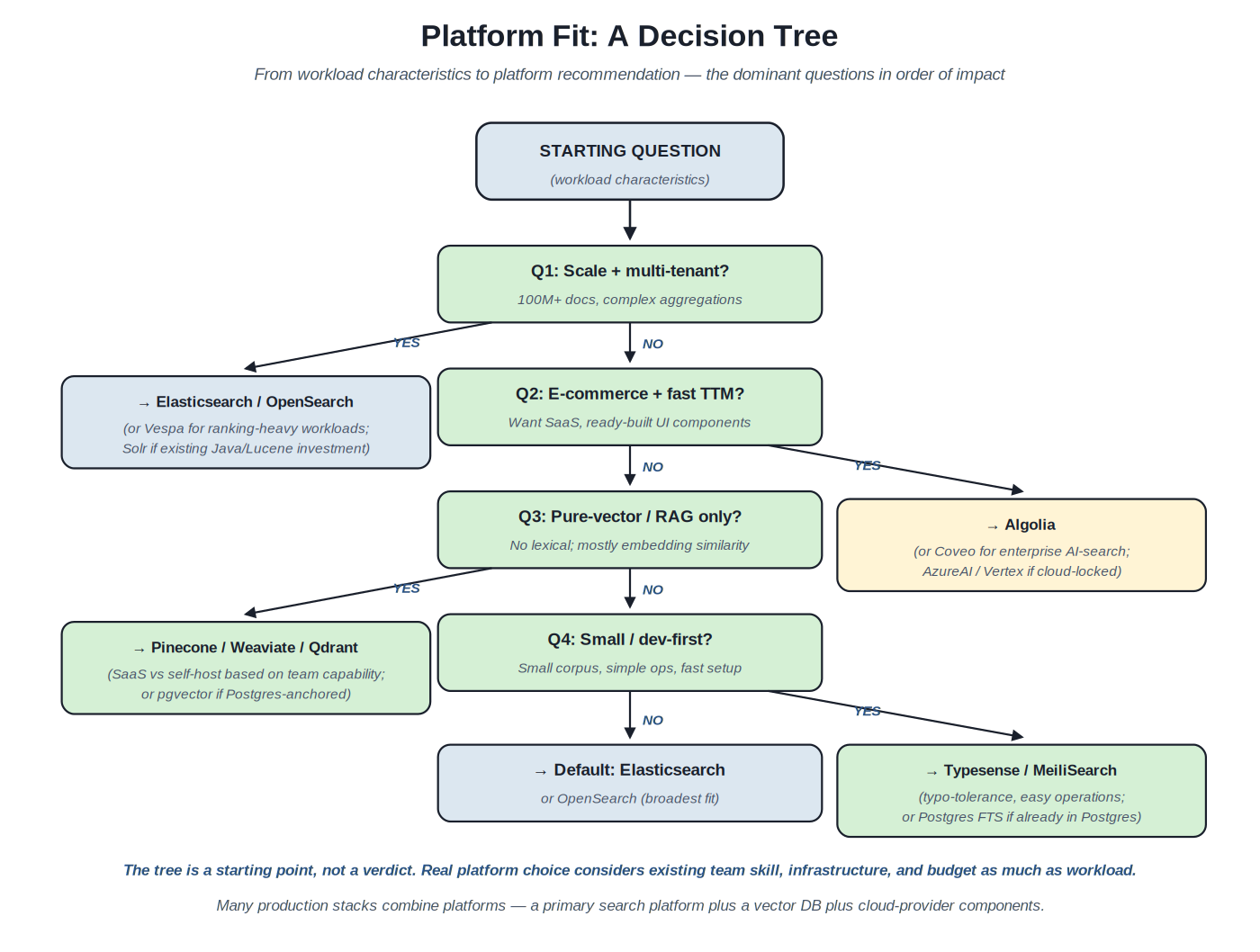
{kind=link}
From workload characteristics to platform recommendation. The tree is a starting point, not a verdict — real platform choice considers existing team skill, infrastructure, and budget.
The new-build decision. For a fresh build with no existing platform commitment, the dominant questions in order of impact. Q1: Scale and multi-tenant complexity — if the workload involves hundreds of millions of documents, complex aggregations, multi-tenant isolation, then Elasticsearch / OpenSearch are the default (or Vespa for ranking-heavy workloads; Solr if there's existing Java/Lucene investment). Q2: E-commerce with fast time-to-market — SaaS platforms with ready-built UI components win; Algolia is the dominant choice; Coveo for enterprise-grade with deeper AI capabilities; the cloud-provider offerings if cloud-locked. Q3: Pure-vector / RAG workload — specialized vector DBs (Pinecone, Weaviate, Qdrant); or pgvector if Postgres-anchored. Q4: Small or dev-first workload — Typesense or MeiliSearch for typo-tolerance focus; or Postgres FTS if already Postgres-anchored. Default: Elasticsearch or OpenSearch for the broadest fit when no specialization criterion dominates.
The tree is a starting point. The questions aren't exhaustive and the answers aren't verdicts. Real platform choices consider existing team skill (a team with deep Elasticsearch experience should think hard before adopting Solr); existing infrastructure (a cloud-locked team has different options than a self-hosting team); budget realities (SaaS platforms have predictable per-query costs that scale with usage; self-hosted platforms have engineer-time costs that don't). Use the tree to narrow candidates, then evaluate the remaining candidates against the workload's specifics.
The migration decision.
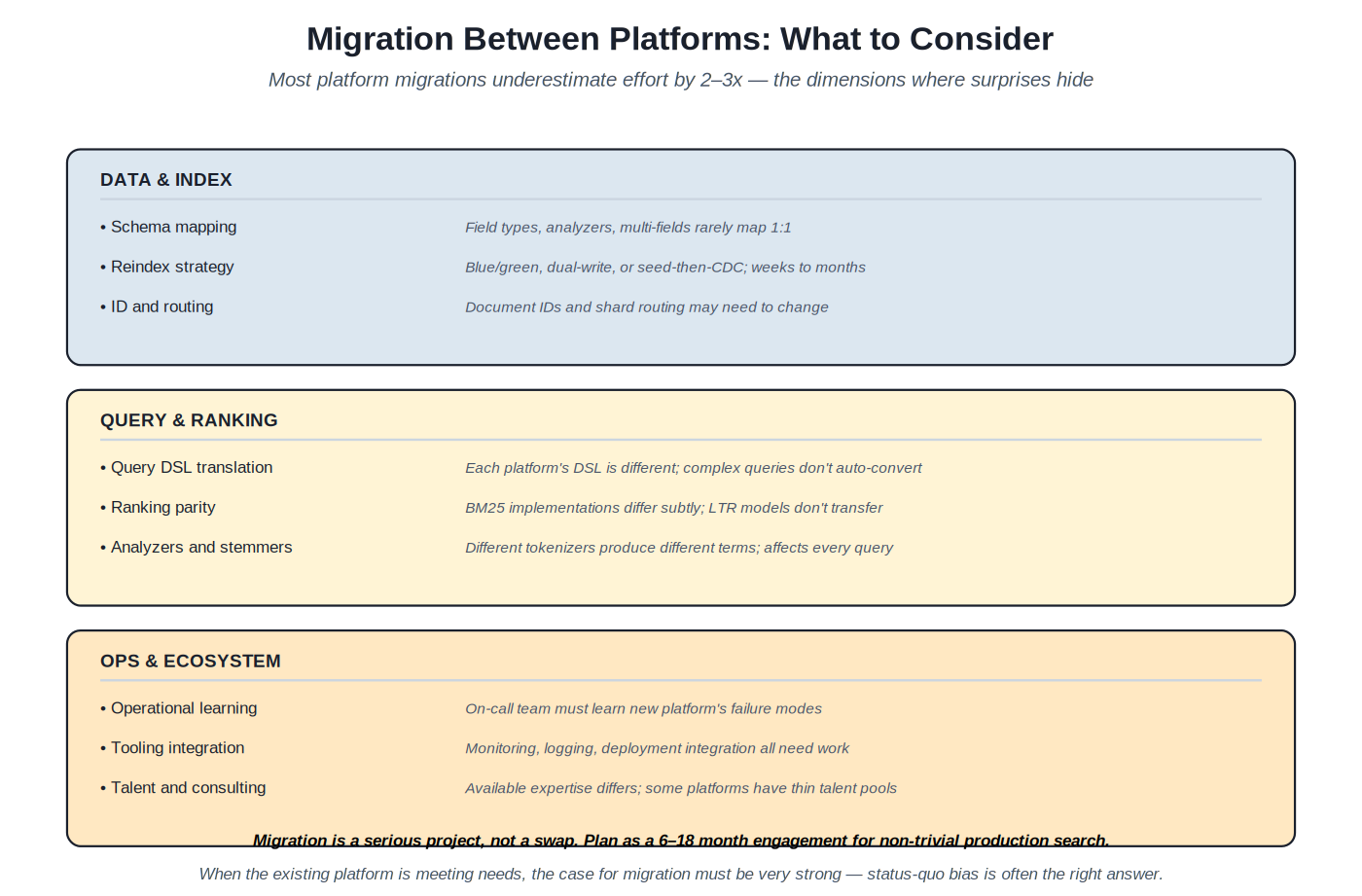
{kind=link}
Most platform migrations underestimate effort by 2–3x. Migration is a serious project, not a swap — plan as a 6–18 month engagement.
Why migrations are expensive. Data and index migration involves schema mapping (field types and analyzers rarely map 1:1 across platforms); reindex strategy decisions (blue/green, dual-write, seed-then-CDC — each with weeks-to-months of implementation work); ID and routing changes. Query and ranking migration involves DSL translation (each platform's query DSL is different and complex queries don't auto-convert); ranking parity (BM25 implementations differ subtly across platforms, LTR models don't transfer); analyzer differences (different tokenizers produce different terms, affecting every query). Operations migration involves the on-call team learning the new platform's failure modes; rebuilding monitoring, logging, deployment integration; finding or training talent for the new platform.
When migration is justified. The case for migration must be strong because the cost is high. Justifications that hold up: the current platform is being deprecated by its vendor (forced migration); the current platform genuinely cannot meet workload needs that have grown beyond its capabilities; the licensing change makes the current platform untenable cost-wise; the team's composition has changed and the platform expertise has been lost. Justifications that often don't hold up under analysis: another platform looks shinier; specific feature comparison favors another platform; vendor pitch was compelling. The discipline is treating the migration question with the seriousness it deserves — a 6–18 month engagement for non-trivial production search.
The status-quo bias question. Status-quo bias — the tendency to prefer the current state — is often the right answer for platform decisions. The current platform has institutional knowledge built around it; the team knows its failure modes; the operational infrastructure is in place; the query and ranking tuning has been done. Replacing all of that requires the new platform to be substantially better, not just marginally better. Production teams that migrate platforms frequently end up with worse total quality than teams that stay on one platform and deepen their expertise.
Chapter 5. The Multi-Platform Reality
In practice, modern production search systems often combine multiple platforms. The primary search platform plus a separate vector database; the primary search platform plus a cache layer; the primary search platform plus an analytics warehouse for query log analysis (Volume 6 Section A). The multi-platform reality is the norm, not the exception, and the patterns for combining platforms deserve attention.
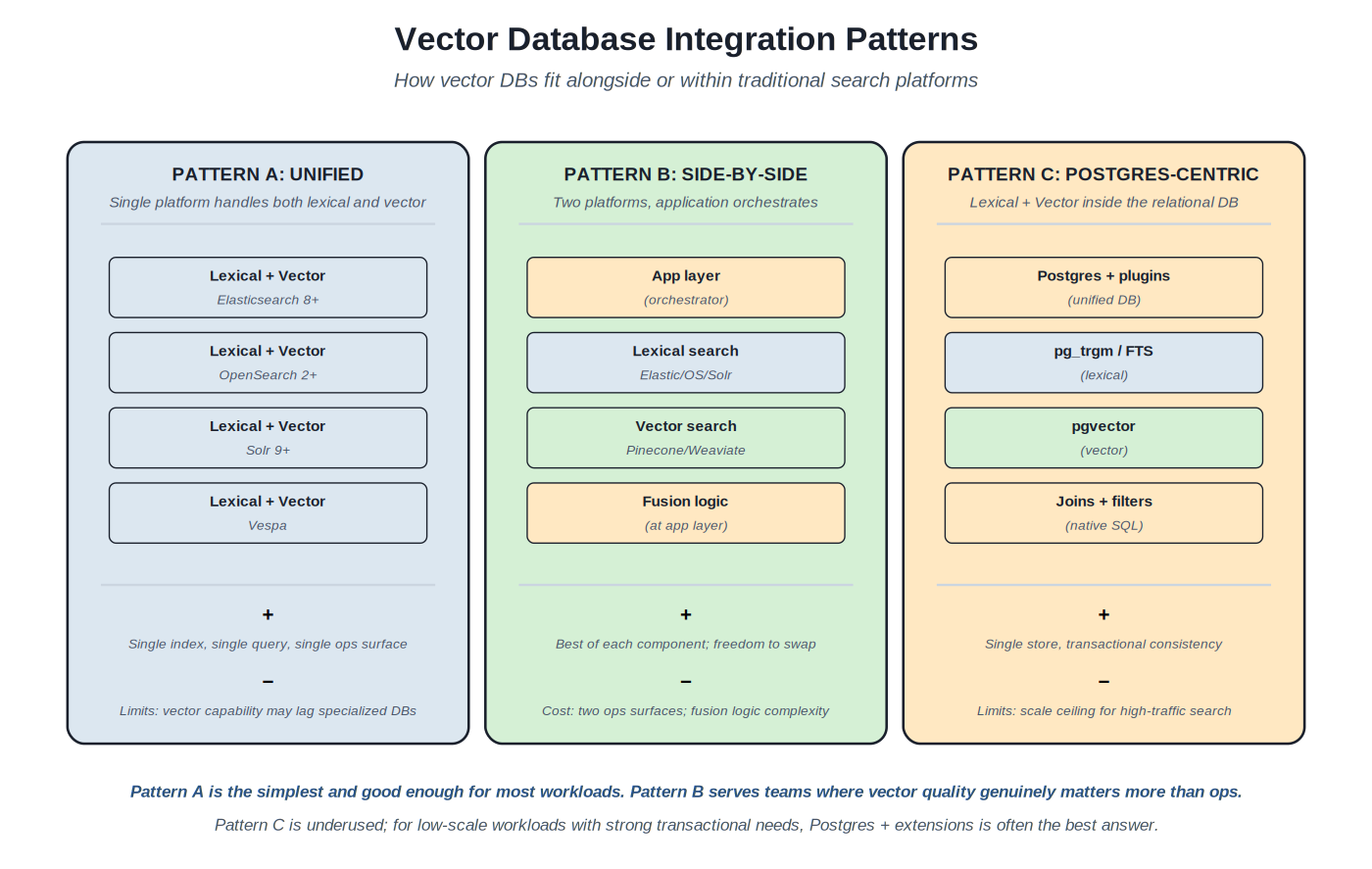
{kind=link}
Three patterns for combining lexical and vector search: unified (single platform), side-by-side (orchestrated at app layer), Postgres-centric (relational database with extensions).
Vector integration patterns. Three patterns recur. Pattern A (unified): a single platform handles both lexical and vector search. Elasticsearch 8+, OpenSearch 2+, Solr 9+, Vespa all support this; a single index serves both query types. Pattern B (side-by-side): the application orchestrates two platforms — a lexical search platform and a vector database — with fusion logic at the application layer (often Reciprocal Rank Fusion or weighted combination). Pattern C (Postgres-centric): both lexical and vector live inside Postgres via extensions (pg_trgm or built-in FTS for lexical, pgvector for vector); the relational database is the single store.
Choosing the integration pattern. Pattern A wins on operational simplicity — single platform, single ops surface, single index. The limit is that the unified platform's vector capability may lag specialized vector DBs (though the gap has narrowed substantially through 2024–2026). Pattern B wins on best-of-breed — each component optimized for its purpose. The cost is two operational surfaces plus the fusion logic complexity at the application layer. Pattern C wins on transactional consistency — the lexical and vector indices update transactionally with the source data. The limit is scale; Postgres-centric search hits ceilings that dedicated search engines don't. For most workloads, Pattern A is the right starting point; Pattern B for workloads where vector quality genuinely matters more than operational simplicity; Pattern C for low-scale workloads with strong transactional needs.
Caching layers. Many production search systems include caching that's technically a separate platform. Application-level cache for common queries (Redis, Memcached). CDN-level cache for global query distribution. Browser-level cache for client-side prefetching. The caching infrastructure is search-adjacent rather than search-platform per se, but it interacts with the search platform substantially. Volume 1 documents the architectural patterns; Volume 6 the operational ones.
Analytics warehouses. The query log analytics infrastructure (Volume 6 Section A) typically lives in a data warehouse — BigQuery, Snowflake, Redshift — not in the search platform itself. Production search systems include the warehouse as a critical component; the search platform writes events to the warehouse for analysis. The choice of warehouse is usually driven by the company's broader data infrastructure rather than by search-specific concerns.
LLM-adjacent components. Modern search stacks increasingly include LLM-adjacent components for query understanding (Volume 2), document enrichment (Volume 3), reranking (Volume 4), and conversational synthesis (Volume 7 Section G). These components — LLM API providers, prompt orchestration frameworks (LangChain, LlamaIndex), evaluation tools (Phoenix, LangSmith, Weights & Biases) — aren't search platforms in the traditional sense but they're part of the modern search stack. The agentic AI series covers them in detail; this volume notes their presence without surveying them.
The implication. The multi-platform reality means platform choice is rarely a single decision. Teams typically choose a primary search platform, plus components for the adjacent capabilities (caching, analytics, LLM integration). Each component has its own platform decision. The discipline documented in this volume applies to each decision, but the decisions are typically not independent — the choice of primary platform affects the natural choices for the adjacent components. A team on Elasticsearch will naturally use AWS or Elastic Cloud infrastructure; a team on AzureAI Search will naturally use Azure-adjacent components. The integration cost of mixing components from different ecosystems is real; production teams typically minimize it by anchoring to one ecosystem where possible.
Part 2 — The Substrates
Eight sections cover the major platform families. Each section opens with a short essay on what its platforms share. Each platform appears as a structured entry: what it is, strengths, limits, best fit, operational notes.
Sections at a glance
- Section A — Elasticsearch and OpenSearch
- Section B — Apache Solr
- Section C — Vespa
- Section D — Algolia
- Section E — Coveo
- Section F — Vector databases (Pinecone, Weaviate, Qdrant, Milvus, Chroma, pgvector)
- Section G — Cloud-provider search (AzureAI, Vertex AI, Kendra)
- Section H — Lightweight and dev-first platforms (Typesense, MeiliSearch) + discovery
Section A — Elasticsearch and OpenSearch
The most-deployed search platforms; forks of the same codebase pre-2021
Elasticsearch (Elastic NV) and OpenSearch (Amazon-stewarded fork) share a common Lucene-based foundation and remained near-identical through 2021–2022 when OpenSearch forked. The platforms have since diverged in specific areas — vector search implementation, licensing model, commercial features — but remain the dominant general-purpose search platforms for non-trivial production workloads. This section treats them together because the platforms still share more than they differ.
Elasticsearch
Elastic NV's commercial-license platform; the most-deployed general-purpose search engine. Open-source through 7.x; Elastic License / SSPL from 7.11 (Jan 2021).
What it is.
Elasticsearch is a Lucene-based distributed search engine and analytics platform. It supports lexical search with rich query DSL, faceted aggregations, dense and sparse vector search, learning-to-rank, geo-spatial queries, and time-series workloads. The platform is the dominant choice for non-trivial production search at scale, with deployments ranging from medium-size product catalogs to massive multi-tenant clusters serving billions of documents.
Distribution model. Self-hosted via the open distribution (with Elastic License terms); managed via Elastic Cloud (Elastic NV's SaaS offering on AWS, GCP, Azure); managed via third parties (some cloud providers offer Elasticsearch as a service under their own terms; this has become rarer since the license change).
Strengths.
Ecosystem depth. Mature ecosystem of plugins, clients (every major language), integrations (Logstash for ingestion, Kibana for analytics and dashboards, Beats for data shippers), and third-party tooling. The ecosystem is the platform's largest asset — nothing else in the space matches its breadth.
Capability breadth. Few capabilities are missing: lexical search with comprehensive query DSL; faceted aggregations rich enough for substantial analytics workloads; vector search with kNN support; learning-to-rank via plugins; geo queries; time-series capabilities. The breadth makes Elasticsearch a defensible default for workloads that don't have a clear specialization need.
Performance at scale. Elasticsearch scales well to large clusters and high throughput; production deployments at major companies (Wikipedia, Netflix, GitHub historically, Etsy, etc.) demonstrate that the platform handles serious scale. Elastic NV invests in performance work continuously.
Talent availability. More engineers know Elasticsearch than any other search platform. Hiring is easier; community support is broader; consulting availability is widest. The talent dimension is genuinely substantial — a platform with thin talent pools costs the team operationally.
Commercial support. Elastic NV provides commercial support, training, and consulting. For enterprises that need accountability, the commercial relationship is valuable; many production deployments find the support investment worthwhile.
Limits.
License complexity since 2021. The Elastic License / SSPL change in 2021 created complexity. The platform isn't open-source in the OSI sense anymore; using it has terms that may matter for some deployments. Many users find the terms acceptable; some find them disqualifying. Teams should review the current license before committing.
Cluster operational complexity at scale. Elasticsearch clusters at scale require operational discipline — shard sizing, JVM tuning, monitoring, cluster topology decisions, version-upgrade choreography. The platform doesn't hide its operational complexity. Production deployments typically need dedicated platform expertise or a managed service.
Resource consumption. Elasticsearch is JVM-based and resource-hungry. Memory requirements (heap plus off-heap), CPU, and disk are all substantial. Cost-per-document tends to be higher than newer specialized platforms; for cost-sensitive workloads, this is a real consideration.
Vector search maturity. Elasticsearch added kNN vector search through 7.x and 8.x; it works well but is less mature than specialized vector databases in specific aspects (high-dimensional embedding performance at very large scale, specialized indexing algorithms). The gap has narrowed substantially through 2024–2026 but specialists may still find dedicated vector DBs preferable.
Pricing in Elastic Cloud. Managed Elastic Cloud pricing is substantial for non-trivial deployments. Teams evaluating it should compare carefully against self-hosting and against managed OpenSearch alternatives.
Best fit for.
Non-trivial production search where the team has or can develop platform expertise. Workloads with broad capability needs — lexical, vector, faceted, analytics — that benefit from a single platform handling all of them. Enterprises that value commercial support and ecosystem breadth.
Less good fit. Cost-sensitive workloads where the JVM overhead and managed service pricing matter. Pure-vector workloads where specialized platforms have meaningful advantages. Workloads where licensing terms are disqualifying.
Operational notes.
Production sizing rule of thumb: 20–50GB primary shards as a reasonable default size; cluster JVM heap typically 32GB max (above this, JVM compressed object pointers stop helping); 1:1 ratio of disk to memory historically (now somewhat relaxed with better caching). Production deployments often run Hot/Warm/Cold/Frozen tiered architectures for cost optimization.
Version upgrade discipline. Major version upgrades (e.g., 7.x → 8.x) require care. Breaking changes accumulate; field mapping changes may require reindexing. Production teams plan upgrades as projects, not as routine patches.
OpenSearch
AWS-stewarded fork of Elasticsearch 7.10; Apache 2.0 licensed; the open-source successor for users who need OSI-compliant licensing.
What it is.
OpenSearch is the Apache 2.0 fork of Elasticsearch created by AWS in 2021 following Elastic's license change. The fork started from Elasticsearch 7.10 and Kibana 7.10 (renamed to OpenSearch Dashboards). The platform has since evolved on its own track, adding features (vector search, ML toolkit, security plugin) and diverging from Elasticsearch in specific areas while retaining substantial compatibility.
Distribution model. Self-hosted via the open-source distribution; managed via Amazon OpenSearch Service (AWS's flagship offering); managed via other cloud providers and third parties (the Apache 2.0 license enables this in ways the Elasticsearch license doesn't).
Strengths.
True open-source under Apache 2.0. For deployments that require OSI-compliant licensing (some government, some enterprise legal departments, some cloud-provider integrations), OpenSearch is the natural Elasticsearch alternative.
AWS stewardship. AWS invests substantially in OpenSearch development and operates Amazon OpenSearch Service as a major managed offering. For AWS-anchored deployments, OpenSearch is the cloud-native choice.
Vector search investment. OpenSearch has invested heavily in vector search capabilities, including the k-NN plugin and integration with multiple vector indexing algorithms (HNSW, IVF, etc.). The vector capability is competitive with Elasticsearch's.
Compatibility with Elasticsearch tooling. Many Elasticsearch clients work against OpenSearch with minor adjustments. Existing Elasticsearch deployments can often migrate to OpenSearch with manageable effort, particularly when starting from Elasticsearch 7.x.
Cost positioning. OpenSearch (especially Amazon OpenSearch Service) is often priced more aggressively than Elastic Cloud, particularly for AWS-anchored deployments where data egress and infrastructure synergies matter.
Limits.
Community size and ecosystem narrower than Elasticsearch. OpenSearch is younger; its community, plugin ecosystem, third-party tooling, and engineer talent pool are smaller than Elasticsearch's. The gap is narrowing but real.
Divergence from Elasticsearch. As the platforms evolve separately, code-level compatibility decreases. Code written against Elasticsearch 7.x clients may need adjustment for OpenSearch; some advanced features differ; documentation is separate. Teams maintaining code across both platforms feel the divergence.
AWS-centric trajectory. Although technically Apache 2.0, OpenSearch development is AWS-led. Some platform decisions favor AWS deployment patterns. Non-AWS deployments of OpenSearch sometimes feel like second-class citizens for specific features.
Commercial support narrower. Beyond AWS, commercial OpenSearch support is thinner than Elasticsearch commercial support. AWS provides excellent support for Amazon OpenSearch Service but only for that managed offering.
Confusion with Elasticsearch in documentation and community discussion. The two platforms share enough history that searches for documentation often surface Elasticsearch material that may or may not apply to OpenSearch. The friction is real for newer engineers.
Best fit for.
AWS-anchored deployments where Amazon OpenSearch Service is the natural choice. Deployments that require Apache 2.0 / OSI-compliant licensing. Teams familiar with Elasticsearch who need to move away from the new license terms. Production deployments where vector search is important and the team values OpenSearch's investment in that area.
Less good fit. Multi-cloud deployments where the AWS-centric trajectory is a concern. Teams that depend on specific Elasticsearch features that haven't been ported to OpenSearch. Teams that value the broader Elasticsearch ecosystem above licensing concerns.
Operational notes.
The OpenSearch project has its own version numbering (started at 1.0 after the fork from Elasticsearch 7.10). Version 2.x is current at the time of writing, with regular feature releases. Production teams should track the OpenSearch release notes for capability additions.
Amazon OpenSearch Service is operationally robust and well-integrated with AWS. For AWS-anchored deployments, the managed service eliminates substantial operational burden — cluster management, version upgrades, scaling are handled by AWS. The trade-off is reduced control over cluster configuration; teams that need detailed cluster tuning may prefer self-hosting.
Section B — Apache Solr
The older Lucene-based platform; less attention than it used to get but still solid for the right workloads
Solr is the Apache Software Foundation's Lucene-based search platform, predating Elasticsearch by several years and once the dominant open-source search engine before Elasticsearch displaced it in mindshare. Solr remains under active development at Apache, with substantial production deployments at companies that adopted it before Elasticsearch's rise. The platform is technically competitive in many areas but has thinner community momentum than Elasticsearch / OpenSearch.
Apache Solr
Apache Software Foundation's Lucene-based search platform. Apache 2.0 licensed. Mature, technically sound, but with thinner community momentum than Elasticsearch / OpenSearch through 2024–2026.
What it is.
Apache Solr is a Lucene-based distributed search engine. It supports comprehensive lexical search with rich query syntax (Lucene query parser, eDisMax), faceted aggregations, vector search (added in Solr 9), learning-to-rank, geo-spatial queries, and time-series workloads. The platform has substantial production deployments at companies including Bloomberg, Cisco, eBay (historically), Instagram, and many enterprises that adopted Solr in the late 2000s and early 2010s.
Distribution model. Apache Solr is open-source under Apache 2.0. SolrCloud (the distributed mode) uses Apache ZooKeeper for cluster coordination. Commercial support is available from vendors including Lucidworks (whose Fusion product is built on Solr), Sematext, and others. Managed Solr services exist but are less widespread than managed Elasticsearch.
Strengths.
Apache 2.0 licensing throughout its history. No license complexity; the platform has been consistently OSI-compliant. For deployments where this matters, Solr is unambiguous.
Schema-driven approach. Solr emphasizes explicit schemas (schema.xml or managed schema APIs) with strong typing of fields. The explicit schema discipline reduces accidental complexity in production deployments where schema drift can cause problems.
Mature LTR support. Solr's learning-to-rank plugin is well-established and battle-tested. For teams investing seriously in LTR, Solr's LTR ecosystem is competitive with Elasticsearch's.
Rich faceting and aggregation capabilities. Solr's faceting was historically a strength; the platform has rich support for term, range, pivot, and hierarchical facets. Production e-commerce deployments often benefit from these capabilities.
Lucidworks Fusion and similar commercial layers. For teams that want commercial features and support, Lucidworks Fusion provides a comprehensive enterprise platform built on Solr. Several other vendors offer similar layers.
Limits.
Community momentum has declined. Solr's mindshare peaked around 2014–2016; Elasticsearch and now OpenSearch dominate community discussion, documentation, blogs, and conference talks. Engineers entering search engineering through 2020–2026 are far more likely to know Elasticsearch than Solr. The talent pool for Solr is correspondingly thinner.
Operational complexity. Like Elasticsearch, Solr clusters require operational discipline — shard management, ZooKeeper operation (an additional system to manage), tuning. The operational tooling around Solr is less mature than Elasticsearch's commercial tooling.
Vector search added later. Solr added native vector search in version 9; the capability is functional but less mature than Elasticsearch's or OpenSearch's. Teams prioritizing vector workloads may find Solr behind.
Documentation and learning resources. Documentation exists and is reasonably comprehensive, but the third-party learning ecosystem (blog posts, tutorials, books, courses) is much smaller than Elasticsearch's. New team members onboarding to Solr have fewer resources.
Vendor and consulting availability. Commercial vendors and consultants who specialize in Solr exist but are fewer than for Elasticsearch / OpenSearch. The dependency on specific vendors (Lucidworks particularly) is real for teams that need commercial support.
Best fit for.
Existing Solr deployments where migration cost outweighs benefits. Teams with deep Solr expertise and operational maturity. Workloads where Solr-specific strengths (explicit schema discipline, LTR maturity, faceting richness) directly benefit. Enterprises with established Lucidworks relationships or other Solr-vendor commitments.
Less good fit. New builds without existing Solr investment. Teams without Solr expertise who would have to develop it. Workloads prioritizing vector search heavily. Workloads benefiting substantially from the Elasticsearch ecosystem of tooling.
Operational notes.
SolrCloud vs standalone. SolrCloud is the distributed mode that uses ZooKeeper for cluster coordination and supports sharding/replication for scale. Standalone Solr is simpler but limited to single-node deployments. Most production deployments use SolrCloud.
The role of Lucidworks. Lucidworks is the commercial entity most associated with Solr; Fusion (their enterprise product) is built on Solr and provides much of what Elastic NV provides for Elasticsearch — management UI, security, analytics, ML integrations. For Solr-anchored enterprises, the Lucidworks relationship is often the natural commercial path.
Section C — Vespa
The Yahoo-origin platform with deep ranking capabilities; powerful but distinct
Vespa is the open-source successor to Yahoo's internal search platform, released as open-source in 2017 and now developed by Vespa.ai (the spun-out company). The platform has a distinctive architecture and a deep focus on ranking and ML — areas where it has capabilities that Elasticsearch and OpenSearch lack. Adoption is narrower than Elasticsearch / OpenSearch but the platform serves serious workloads at companies including Yahoo (historically), Spotify, OK Cupid, and Vinted.
Vespa
Vespa.ai's open-source platform descended from Yahoo's internal search engine. Apache 2.0 licensed. Powerful but architecturally distinct from Elasticsearch / Solr.
What it is.
Vespa is a distributed search and recommendation engine designed for serving big-data online applications. It supports lexical search, vector search, structured data queries, and ranking-heavy workloads with native multi-stage ranking pipelines, tensor operations for ML scoring, and tightly integrated ML model serving. The platform's heritage is Yahoo's Vespa internal platform (powering Yahoo Mail, Yahoo News, advertising) before being open-sourced in 2017.
Distribution model. Open-source under Apache 2.0 for self-hosted deployments; managed via Vespa Cloud (Vespa.ai's SaaS offering). The platform has a steeper learning curve than Elasticsearch but offers correspondingly deeper capabilities for ranking-heavy workloads.
Strengths.
Ranking depth. Vespa's ranking framework is its standout capability. Multi-stage ranking pipelines, native tensor operations for ML scoring (including direct LightGBM, XGBoost, and ONNX model serving), expressive ranking expressions — all natively integrated rather than added via plugins. Production teams with serious ranking needs (recommendation systems, large e-commerce search) find Vespa's capabilities meaningfully ahead of alternatives.
Vector + lexical from day one. Unlike Elasticsearch / Solr / OpenSearch (which added vector later), Vespa designed for combined lexical and vector workloads. The integration is tighter and the performance characteristics are stronger for hybrid workloads.
Real-time updates with ranking. Vespa supports real-time document updates while maintaining ranking quality. Many search engines compromise one for the other; Vespa handles both well, which matters for workloads with frequent content updates.
Operational architecture. Vespa's architecture (with distinct content, container, and config nodes) provides cleaner separation than Elasticsearch's. The architecture is more complex initially but scales cleanly for the workloads it's designed for.
Trino-style query language. Vespa's YQL (Yahoo Query Language) is SQL-like, more familiar to data engineers than Elasticsearch's JSON DSL. Teams from data engineering backgrounds often find Vespa's query model more natural.
Limits.
Learning curve. Vespa's conceptual model is distinct from Lucene-based platforms. Teams transitioning from Elasticsearch / Solr find the learning curve substantial. The investment pays off for the right workloads but is genuinely an investment.
Talent pool. Engineers experienced with Vespa are far rarer than Elasticsearch engineers. Hiring is harder; community support is smaller; consulting availability is much narrower. For teams without existing Vespa expertise, the talent gap is a real cost.
Ecosystem breadth. Plugin ecosystems, client libraries, third-party integrations are thinner than Elasticsearch's. Vespa has the essentials but lacks the long tail of community contributions.
Documentation and learning resources. Vespa's documentation has improved substantially since open-sourcing but remains less abundant than Elasticsearch's. Blog posts, tutorials, conference talks all exist but at smaller volume.
Operational complexity for smaller deployments. Vespa's architectural cleanliness benefits large deployments but adds overhead for smaller ones. Teams without scale to justify the architectural sophistication may find Elasticsearch simpler to operate.
Best fit for.
Workloads where ranking depth is the primary value driver — recommendation systems, large-scale e-commerce search where ranking quality differences directly affect revenue. Workloads with serious ML integration needs where Vespa's native tensor support and model serving matter. Teams willing to invest in Vespa expertise to capture its ranking advantages.
Less good fit. Workloads where ranking is straightforward and Elasticsearch's defaults are sufficient. Teams without scale to justify the learning curve. Teams that need broad ecosystem support and easy talent availability.
Operational notes.
Vespa's heritage at Yahoo means it has been battle-tested at very large scale (powering Yahoo Mail spam classification, Yahoo News personalization, ad serving). The platform handles workloads that Elasticsearch would struggle with at the same scale.
Vespa Cloud provides managed service for teams that want the platform's capabilities without the operational burden. For teams new to Vespa, starting on Vespa Cloud is often the right entry point.
Section D — Algolia
The SaaS search platform with strong UX tooling and e-commerce focus
Algolia is a SaaS search platform founded in 2012, originally focused on instant search experiences for e-commerce and content. The platform has expanded substantially since but retains its core strengths: fast time-to-market for production search, strong UX component libraries, predictable SaaS operational model. For teams that value these properties over the flexibility of self-hosted platforms, Algolia is often the right choice.
Algolia
SaaS search platform with strong e-commerce and content-search focus. Predictable pricing per query; mature UX component libraries (Autocomplete, InstantSearch, React InstantSearch, etc.).
What it is.
Algolia is a fully managed search-as-a-service platform. It provides search APIs, hosted indices, and front-end component libraries that combine to deliver production search without operational burden on the customer. The platform's technical foundation is proprietary (not Lucene-based); it's designed from the ground up for the SaaS use case rather than being a hosted version of an open-source engine.
Distribution model. Pure SaaS; Algolia operates the infrastructure. Customers configure indices, push documents via API, query via API. Multiple data centers globally for low-latency distributed search. Pricing is typically based on records indexed and operations performed (queries plus index writes).
Strengths.
Time to market. Algolia is the fastest way to get production search running. The component libraries (Algolia Autocomplete, React InstantSearch, Vue InstantSearch) include polished UI components for the common search surfaces — search bar with autocomplete, faceted results, pagination, sort. Teams ship in days what would take weeks on self-hosted platforms.
UX component libraries. The Algolia front-end libraries are genuinely excellent. They handle the WAI-ARIA accessibility, the state management, the URL synchronization, the keyboard navigation — all the patterns Volume 7 documents. Even teams not using Algolia's backend can use the front-end libraries against other backends (a less-known but real option).
Operational simplicity. As a SaaS, Algolia eliminates the operational burden of running search infrastructure. No cluster to manage; no version upgrades; no shard sizing. For teams without dedicated search-platform expertise, this trade-off is often worth the cost.
Performance and global distribution. Algolia's infrastructure prioritizes low-latency queries with global presence. P95 query latency is consistently very low across geographies; this is harder to achieve with self-hosted platforms without substantial investment in CDN-like architecture.
E-commerce and content focus. The platform's features prioritize the e-commerce and content-search use cases — typo tolerance, synonyms, merchandising rules, A/B testing built into the platform, analytics dashboards focused on conversion. Teams in these domains find the platform fits their needs without extensive custom development.
Limits.
Cost at scale. Algolia's SaaS pricing becomes expensive at scale. The per-query and per-record pricing model is predictable but adds up; production deployments at high query volumes can find self-hosting more economical. The break-even point varies but is often around the level where teams need dedicated search platform engineers anyway.
Vendor lock-in. The platform's API is proprietary; moving off Algolia requires substantial work (re-implementing search logic against a different backend, retraining the team on a different platform). The lock-in is real and should be considered when adopting.
Less flexibility for unusual workloads. Algolia is opinionated about how search should work; this is a strength for common workloads but a limit for unusual ones. Workloads that need deep customization (custom ranking models, specialized query understanding, unusual schema) hit limits that don't exist with Elasticsearch.
Data sovereignty constraints. Algolia operates from specific data centers; for workloads with strict data sovereignty requirements (specific geographies, specific compliance regimes), the SaaS model may not be acceptable.
Vector search added later. Algolia added vector search and AI capabilities through 2023–2024; the capability is functional but the platform's heritage is lexical search, and specialists may find dedicated vector platforms preferable for vector-heavy workloads.
Less common at very large enterprise scale. While Algolia is widely used in mid-market and consumer products, very large enterprise deployments more often choose Elasticsearch / OpenSearch / Coveo / Vespa. Algolia's positioning is strong at the medium-scale e-commerce and content-search use case rather than the largest workloads.
Best fit for.
E-commerce and content search where time-to-market matters and operational simplicity is valued. Mid-market companies without dedicated search platform engineers. Teams that benefit from Algolia's strong UX component libraries. Workloads where Algolia's opinionated approach matches the team's needs.
Less good fit. Very large enterprise workloads where Algolia pricing becomes prohibitive. Workloads requiring deep customization beyond what Algolia's API supports. Teams that need vector search as the primary capability. Workloads with strict data sovereignty requirements that Algolia's infrastructure can't meet.
Operational notes.
The InstantSearch and Autocomplete libraries are open-source and usable against non-Algolia backends. Teams that like the UX libraries but want a different backend can use them with adapters (with implementation work).
Algolia's analytics and merchandising tooling are tightly integrated with the search platform. Teams that adopt Algolia get useful operational dashboards by default; this is a less-discussed strength compared to running the equivalent reporting against self-hosted Elasticsearch.
Section E — Coveo
The commercial AI-search platform; strong enterprise positioning
Coveo is a commercial AI-search platform that went public in 2021. It positions itself as the AI-powered search and recommendation platform for enterprise applications, particularly for customer-facing e-commerce, customer service / support, and workplace search use cases. The platform is well-suited to enterprises that want substantial AI capabilities (semantic search, personalization, machine-learning ranking) without building them from scratch.
Coveo
Commercial AI-search platform (TSX:CVO) with strong enterprise positioning. SaaS deployment model; native ML for ranking, personalization, and intent detection.
What it is.
Coveo is a proprietary SaaS search and recommendation platform. It provides indexing, search, ranking, ML-driven personalization, analytics, and merchandising for enterprise use cases — e-commerce search, customer service portals, employee intranet search. The platform integrates substantial machine learning capabilities natively (rather than via plugins or external models), positioning itself as the AI-search platform for enterprises that want these capabilities without building them.
Distribution model. Pure SaaS, operated by Coveo. Customers configure indices, push data via connectors or API, query via search APIs. Coveo provides connectors for common enterprise systems (Salesforce, ServiceNow, SharePoint, web crawling, e-commerce catalogs). Pricing is typically enterprise contracts based on indexed volume, query volume, and feature tier.
Strengths.
Native ML capabilities. Coveo's ML capabilities — Automatic Relevance Tuning (ART), Query Suggestions (QS), Dynamic Navigation Experience (DNE), Content Recommendations (CR), Product Recommendations (PR) — are built into the platform rather than added later. The capabilities work out of the box (with sufficient query data); they don't require the team to build LTR pipelines from scratch.
Enterprise feature depth. Security and compliance features (SAML SSO, granular access control, audit logging), connectors for common enterprise systems, multi-tenant support, content security models that respect source-system permissions — all mature and well-developed. Enterprises evaluating Coveo find that the enterprise checklist items are addressed.
Out-of-the-box analytics. Coveo provides comprehensive analytics dashboards focused on search quality (NDCG, MRR, zero-result rates) and business outcomes (conversion attribution, revenue per session). The dashboards are usable without building custom analytics infrastructure, which is a real advantage over Elasticsearch / OpenSearch.
Merchandising tooling. The platform's merchandising layer (rules, boosting, A/B testing of merchandising experiments) is mature and usable by business stakeholders, not just engineers. For e-commerce teams where merchandisers actively tune search, the tooling matters.
Customer service strength. Coveo has particular strength in customer service / support search — deflection-focused experiences, knowledge base search, agent-assist applications. The integration with Salesforce Service Cloud is mature; enterprises using Salesforce often adopt Coveo for the search layer.
Limits.
Cost. Coveo is an enterprise platform with enterprise pricing. Annual contracts are substantial (typically six-figure minimums); the platform is not appropriate for cost-sensitive deployments. The pricing is justified for the right enterprise contexts but disqualifies many use cases.
Vendor lock-in. As a fully proprietary SaaS, switching off Coveo is substantial work. Custom Coveo configurations, ML models trained on Coveo data, integrations with Coveo APIs all need replacement. Teams adopting Coveo should plan as a multi-year commitment.
Less flexibility than Elasticsearch. Coveo is opinionated about how search should work; this is a strength for the workloads it targets but a limit for unusual ones. Workloads needing deep customization beyond what Coveo's configuration supports hit ceilings that don't exist with self-hosted platforms.
Narrower community. The Coveo developer and engineering community is much smaller than Elasticsearch's. Documentation is enterprise-style (comprehensive but less abundant than open community-written content). Talent for Coveo development is specialized; consulting availability is narrower.
Limited self-service for non-standard use cases. The platform's strengths are in the use cases it targets; for use cases outside that envelope (specialized search domains, unusual schema requirements, non-enterprise patterns), Coveo may not be the right choice.
Pricing complexity for evaluation. The enterprise contract model makes Coveo harder to evaluate cheaply. Trial deployments exist but require sales engagement; teams can't "just try it" the way they can with open-source platforms or even with Algolia's low-tier plans.
Best fit for.
Enterprise e-commerce where the ML capabilities (ART, recommendations) provide substantial value out of the box. Customer service search and support deflection use cases, particularly with Salesforce Service Cloud integration. Enterprise workplace search where security models and connector breadth matter. Bass Pro Shops and similar enterprise retail engagements where the ML-driven relevance investment is core to the platform value.
Less good fit. Small-team or cost-sensitive deployments. Workloads outside Coveo's target use cases (specialized domains, deep customization needs). Teams that need open-source licensing or want to avoid SaaS lock-in.
Operational notes.
Coveo went public on TSX in November 2021; the platform has been investing in expanded ML capabilities and broader market positioning since. Recent announcements (through 2024–2026) have emphasized generative AI integration and conversational search experiences.
Coveo's strongest competitor in the enterprise AI-search space is Bloomreach (for e-commerce specifically) and Glean (for workplace search). The competitive positioning depends heavily on the specific use case.
Section F — Vector databases
The specialized platforms for embedding-based search; consolidated through 2024–2026
Vector databases emerged as a category through 2019–2022 as embedding-based search became production-viable. The category has consolidated through 2024–2026 as general-purpose search platforms (Elasticsearch, OpenSearch, Solr, etc.) added vector capabilities, reducing the need for separate vector DBs in many cases. The dedicated vector platforms remain relevant for workloads where vector quality and scale are the primary concerns; they are increasingly secondary for general-purpose search.
Pinecone, Weaviate, Qdrant, Milvus, Chroma (the dedicated vector DBs)
The specialized vector platforms. Each has its own positioning but the category-level patterns are similar.
What it is.
Vector databases are specialized search platforms designed for embedding-based retrieval. They store dense vectors (typically 384, 768, 1024, 1536, or 3072 dimensions depending on the embedding model), support approximate nearest neighbor (ANN) search via algorithms like HNSW (Hierarchical Navigable Small World), IVF (Inverted File Index), and product quantization, and provide metadata filtering alongside vector similarity. The category emerged with the RAG (retrieval-augmented generation) wave through 2022–2024 and has become a substantial software category.
The major platforms: Pinecone (SaaS-only, founded 2019, the dominant SaaS choice), Weaviate (open-source + cloud, founded 2019, strong on hybrid search and modular ML integration), Qdrant (open-source + cloud, founded 2020, Rust-based with strong performance), Milvus (open-source + Zilliz Cloud, founded 2019, originally from Zilliz, popular in China), Chroma (open-source + cloud, founded 2022, dev-first positioning for RAG applications). Each platform has its specific strengths but the category-level capabilities are similar.
Strengths.
Specialized vector performance. The dedicated platforms have invested heavily in ANN algorithms, index structures, and query performance for vector workloads. For very large vector collections (hundreds of millions of vectors) or very high query throughput, the dedicated platforms typically outperform general-purpose search engines.
Hybrid search support. Most dedicated vector DBs now support hybrid (lexical + vector) search via various mechanisms (BM25 plus vector, sparse + dense vectors, learned sparse representations like SPLADE). The hybrid capabilities have matured substantially through 2024–2026.
Metadata filtering. Each platform supports filtering vector search by metadata attributes — filter by tenant, by category, by date range, etc. — a critical capability for production workloads. Implementation quality varies; this is one of the dimensions where the platforms differentiate.
Developer experience. Most of the dedicated platforms have invested in clean APIs and SDKs (Python first, with Node, Go, Java following). For teams building RAG applications, the dedicated platforms are typically easier to integrate than retrofitting vector search onto a general-purpose engine.
Pinecone managed service maturity. Pinecone specifically is mature as a managed service — well-operated, well-documented, well-supported. For teams that want vector search without operational burden, Pinecone is often the path of least resistance.
Open-source options. Most of the category (Weaviate, Qdrant, Milvus, Chroma) is open-source; teams can self-host or use managed services. The open-source option matters for teams with licensing or data-residency constraints.
Limits.
Operational overhead for self-hosted. Self-hosting any of these platforms adds a separate operational surface to manage. Most teams already operating a general-purpose search platform need a strong reason to add a second one.
Reduced advantage as general-purpose platforms add vector support. The gap between dedicated vector DBs and general-purpose platforms has narrowed substantially. Elasticsearch 8+, OpenSearch 2+, Solr 9+ all have functional vector support that's sufficient for most workloads. The case for a dedicated vector DB has weakened correspondingly.
Workload patterns favoring general-purpose. Most production search workloads benefit from combining vector with rich lexical search, filtering, aggregations — capabilities that general-purpose engines provide natively. For these workloads, the cost of orchestrating two platforms (Pattern B from Vol 8 Chapter 5) often outweighs the vector-quality benefits.
Pricing volatility. Vector DB pricing models have evolved substantially as the category matured. Pinecone's pricing changes in 2023–2024 caused some customer frustration. Teams adopting these platforms should expect pricing models to continue evolving.
Smaller ecosystems. None of the dedicated vector DBs have ecosystems comparable to Elasticsearch / OpenSearch. Client libraries are good but not as broad; community resources exist but are smaller; commercial support is more concentrated with the vendor.
Consolidation expected. The category is over-crowded; consolidation through 2025–2027 is likely. Some current vendors will be acquired, some will fail, some will pivot. Teams adopting today should plan for the possibility that their chosen vendor changes ownership or focus.
Best fit for.
Pure-vector workloads where embedding similarity is the primary capability needed and the team doesn't need rich lexical search. RAG applications for chatbots and agents where the vector DB is one component of a larger stack and integration simplicity matters. Workloads at vector scale (hundreds of millions of vectors) where dedicated platform performance is genuinely needed. Teams already on a non-search-platform stack (Postgres-anchored or NoSQL-anchored) where adding a vector DB is cleaner than adopting Elasticsearch.
Less good fit. General-purpose search workloads that combine lexical and vector. Workloads where the team already operates a general-purpose search platform that has functional vector support. Cost-sensitive workloads where the second operational surface isn't justified.
Operational notes.
pgvector as alternative. Postgres + pgvector extension provides vector search inside Postgres. For Postgres-anchored teams at low-to-moderate scale, pgvector is often the right answer — it eliminates the separate platform entirely. pgvector has matured substantially through 2024–2026 and competes with dedicated vector DBs for workloads up to tens of millions of vectors.
The hybrid search frontier. Hybrid search (lexical + vector + reranking) is where most production search is heading. The platforms (both vector DBs and general-purpose engines) that handle hybrid well will benefit; those that handle only one mode well will be specialized.
Embedding model considerations. Vector DB choice often matters less than embedding model choice. The quality of the underlying embedding model (OpenAI text-embedding-3, Cohere embed-v3, Voyage AI, open-source alternatives) substantially affects retrieval quality regardless of which vector DB serves the embeddings. Teams should make the embedding model decision before or alongside the vector DB decision.
Section G — Cloud-provider search
Microsoft AzureAI Search, Google Vertex AI Search, Amazon Kendra
Each of the major cloud providers offers search services optimized for their cloud ecosystem. These services compete with general-purpose search platforms but optimize for cloud-native deployment patterns and integration with the provider's broader AI / ML services. For cloud-anchored deployments, the provider's search service is often the natural choice; for multi-cloud or on-prem deployments, the lock-in is real.
Microsoft AzureAI Search
Microsoft's managed search service (formerly Azure Cognitive Search). Tightly integrated with Azure ecosystem and Microsoft AI services.
What it is.
Microsoft AzureAI Search is the managed search service on Microsoft Azure. The platform supports lexical search, vector search (added through 2023–2024), faceted aggregations, and integration with Microsoft's AI services (Azure OpenAI, Azure Document Intelligence, cognitive skills for content enrichment). Originally called Azure Cognitive Search; renamed to AzureAI Search around 2023–2024 to align with Microsoft's broader AI branding.
Strengths.
Azure integration. The platform integrates tightly with Azure services — Azure Blob Storage for documents, Azure Functions for processing, Azure OpenAI for embeddings, Azure Monitor for observability. Azure-anchored deployments find the integration substantially reduces development effort.
Cognitive skills. The platform's cognitive skills pipeline (OCR, entity extraction, key phrase extraction, sentiment analysis, custom skills) provides content enrichment as part of the indexing pipeline. For workloads with diverse content types (PDFs, images, audio), the built-in skills are valuable.
RAG-friendly. AzureAI Search has invested in RAG-pattern support: vector + lexical hybrid, semantic ranking, and integration patterns with Azure OpenAI for chatbot and agent applications. Microsoft's Copilot products lean on this stack heavily.
Enterprise SLAs and compliance. The platform meets enterprise compliance requirements (SOC, ISO, HIPAA, FedRAMP available in specific configurations) that matter for regulated industries.
Limits.
Cloud lock-in. AzureAI Search is Azure-only. Multi-cloud or hybrid-cloud deployments must accept this constraint or use a different platform.
Cost at scale. Pricing is per service tier (Basic, Standard, Standard S2, S3, Storage Optimized); costs scale with index size and query volume. At scale, AzureAI Search can be expensive; the value depends on whether the Azure-integration benefits justify the cost.
Smaller community. The platform's community is much smaller than Elasticsearch / OpenSearch. Documentation is comprehensive (Microsoft-style enterprise documentation) but community-written resources are thinner.
Feature gaps vs Elasticsearch. Several Elasticsearch capabilities (some advanced aggregations, some specific query types, some plugin types) are missing or differently implemented. Teams migrating from Elasticsearch encounter feature gaps that need workarounds.
Less platform flexibility. As a managed service, AzureAI Search exposes specific configuration knobs; users can't tune the underlying engine the way self-hosted Elasticsearch allows.
Best fit for.
Azure-anchored deployments where integration with Azure services provides substantial value. Microsoft-stack enterprises with existing Azure investment. RAG applications using Azure OpenAI where the integrated stack reduces engineering effort. Workloads benefiting from the cognitive skills enrichment pipeline.
Less good fit. Multi-cloud deployments. Cost-sensitive workloads at scale. Workloads requiring deep customization beyond what the managed service supports.
Google Vertex AI Search
Google's search offering, evolved from Google Cloud Discovery Engine. Strong integration with Google's ML infrastructure and Search-quality investments.
What it is.
Vertex AI Search is Google's managed enterprise search service, formerly branded Discovery Engine. The platform leverages Google's search technology and Vertex AI ML stack to provide retrieval, ranking, and generative-AI synthesis. Positioning is enterprise search, e-commerce search, and document/media search with built-in conversational capabilities.
Strengths.
Google search heritage. Vertex AI Search benefits from Google's decades of search-quality investment. For many workloads, default retrieval and ranking quality are strong without substantial tuning.
Generative AI integration. The platform has invested heavily in RAG-style generative search experiences — synthesized answers with citations, multi-turn conversational queries, grounded responses on the customer's indexed content. For teams building generative search experiences, the integrated capabilities reduce engineering effort.
Vertex AI ecosystem. Integration with Vertex AI ML infrastructure — embeddings, custom model serving, fine-tuning — provides a coherent stack for AI-augmented search.
Multi-modal support. The platform supports text, image, and video search with appropriate modality-aware models. Workloads with multi-modal content benefit from the unified platform.
Limits.
Cloud lock-in. GCP-only. Multi-cloud deployments must accept this.
Pricing complexity and rate. Vertex AI Search pricing is enterprise-tier and complex; cost forecasting is harder than for some alternatives.
Smaller ecosystem and community. Among the major cloud providers, Google has the smallest search-platform community. Documentation is comprehensive (Google-style) but third-party resources are thinner.
Newer platform with less battle-testing. Vertex AI Search's current form is newer than Elasticsearch or AzureAI Search; production deployments at scale are fewer, and the longer-term operational characteristics are less proven.
Limited customization. As with other cloud-provider managed services, customization depth is limited compared to self-hosted platforms.
Best fit for.
GCP-anchored deployments where integration with Google's AI stack matters. Workloads where generative search experiences are central and the integrated capabilities reduce engineering effort. Multi-modal workloads benefiting from Google's investment in image and video search.
Less good fit. Multi-cloud deployments. Teams that value mature community support and broad ecosystem. Workloads requiring deep customization of retrieval and ranking.
Amazon Kendra and the AWS Search Stack
AWS's enterprise search service. Distinct from Amazon OpenSearch Service — Kendra is the higher-level managed enterprise search; OpenSearch is the Lucene-based platform.
What it is.
Amazon Kendra is AWS's managed enterprise search service for unstructured content — documents, SharePoint, Salesforce, web content, custom sources. It provides connector-based ingestion, natural language understanding, and Q&A-style query understanding. Distinct from Amazon OpenSearch Service (which is the Lucene-based platform covered in Section A).
Positioning. Kendra targets enterprise knowledge search use cases — employees searching across corporate content, customer service teams accessing knowledge bases, internal tools that need search over unstructured sources. It's not positioned as a general-purpose search engine; it's positioned as enterprise unstructured-content search with built-in NLP.
Strengths.
Connector ecosystem. Kendra includes connectors for many enterprise systems (SharePoint, Confluence, Salesforce, ServiceNow, Box, OneDrive, web crawler) that handle the ingestion details. Enterprise deployments save substantial effort vs building these from scratch.
AWS integration. Native integration with AWS services — S3, Lambda, IAM, CloudWatch — makes Kendra a natural fit for AWS-anchored deployments.
Q&A semantic search out of the box. Kendra's default query handling includes natural language understanding for question-answering queries; users can ask questions and get extracted answers without complex configuration.
Limits.
Cost. Kendra is expensive at any scale; the per-month pricing is high relative to alternatives. Enterprise pricing model that doesn't fit smaller deployments.
Limited customization. As a high-level managed service, Kendra exposes less configuration than OpenSearch or Elasticsearch. Workloads requiring custom ranking models or specific query handling hit limits quickly.
Less performant for general-purpose search. Kendra is optimized for unstructured content search, not for high-throughput e-commerce or content-website search workloads. Teams needing those workloads typically use OpenSearch instead.
Smaller community. Kendra's community is smaller than Elasticsearch / OpenSearch by orders of magnitude. The platform is less learnable from public resources.
Lock-in. Like other cloud-provider managed services, switching off Kendra is substantial work.
Best fit for.
AWS-anchored enterprise deployments needing search over unstructured content from common enterprise sources. Knowledge-management use cases where the connector ecosystem provides direct value. Teams that prioritize ease of deployment over cost optimization.
Less good fit. Cost-sensitive deployments. General-purpose e-commerce or content search (use Amazon OpenSearch Service instead). Non-AWS deployments.
Operational notes.
AWS has multiple search-related services beyond Kendra: Amazon OpenSearch Service (covered in Section A), Amazon CloudSearch (older managed search service, largely superseded), and various ML services (Comprehend, Translate) that integrate with the search services. Teams choosing within AWS often have several services to evaluate.
Section H — Lightweight platforms and discovery
Typesense, MeiliSearch, and resources for tracking the platform landscape
Beyond the major platforms, several lightweight options serve specific niches — typo-tolerance, dev-first deployments, small-scale workloads. This section covers them briefly and provides resources for tracking the broader platform landscape as it evolves.
Typesense and MeiliSearch (the dev-first lightweight platforms)
Open-source search engines designed for developer experience, typo tolerance, and easy deployment. Sweet spot is small-to-medium workloads where ops simplicity matters.
What it is.
Typesense (founded 2017) and MeiliSearch (founded 2018) are open-source search engines that emerged with a developer-experience focus. Both prioritize: instant search with sub-50ms response times; strong typo tolerance out of the box; easy deployment (single binary, simple operations); good documentation aimed at developers building products rather than search specialists.
Distribution model. Both are open-source (Typesense Apache 2.0; MeiliSearch MIT). Both offer managed cloud services (Typesense Cloud, MeiliSearch Cloud). Both can be self-hosted with minimal operational burden — single binary, no JVM, modest resource requirements.
Strengths.
Developer experience. Both platforms invest heavily in DX — clean APIs, good documentation, sensible defaults. For small teams adding search to a product without dedicated search expertise, the friction is much lower than Elasticsearch.
Operational simplicity. Both run as single binaries with modest resource needs. Production deployments at small-to-medium scale can be operated by developers without dedicated platform engineering. No JVM tuning, no shard sizing.
Typo tolerance. Strong built-in fuzzy matching and typo correction. For workloads where typo handling matters (consumer search, mobile users), the defaults work well without tuning.
Instant search defaults. Both platforms are optimized for the search-as-you-type pattern that Volume 7 Section A documents. Latency is excellent without manual optimization.
Cost positioning. For small-to-medium workloads, self-hosted Typesense or MeiliSearch is far cheaper than Algolia or managed Elasticsearch. The cloud offerings are also positioned at the lower end of the pricing range.
Limits.
Scale ceilings. Neither platform is designed for the largest workloads. Production deployments at very large scale (hundreds of millions of documents, very high query rates) use Elasticsearch / OpenSearch / Vespa. Typesense and MeiliSearch are appropriate for workloads up to tens of millions of documents.
Feature breadth. The platforms intentionally have narrower feature sets than Elasticsearch. Some Elasticsearch-style aggregations, plugin ecosystems, advanced analytics are not present. Teams that need these features should choose differently.
Smaller community. While the developer-experience focus has built loyal communities, both platforms have communities orders of magnitude smaller than Elasticsearch. Stack Overflow questions, blog posts, conference talks are correspondingly fewer.
Talent availability. Engineers experienced with these platforms exist but are far fewer than Elasticsearch engineers. Hiring for these platforms specifically is harder; teams typically hire generalists and have them learn the platform.
Enterprise readiness varies. Both platforms have made progress on enterprise features (security, multi-tenancy, audit logging) but lag the major platforms. Enterprise deployments need to verify the platform meets their specific compliance and security requirements.
Best fit for.
Small-to-medium product searches where developer experience matters and operational simplicity is valued. Consumer applications where instant search and typo tolerance are user-visible quality drivers. Cost-sensitive deployments where Algolia is too expensive but Elasticsearch is too complex. Internal tools where ease of deployment matters more than scale.
Less good fit. Very large scale workloads. Enterprise deployments requiring specific compliance features. Workloads needing capabilities outside the platforms' narrower feature sets.
Resources for tracking the platform landscape
Where to follow platform evolution as it continues through 2025–2027
What it is.
The platform landscape continues to evolve rapidly. Following the right sources keeps the practitioner's mental model current as platforms add features, change licenses, or pivot positioning.
Strengths.
Vendor documentation and release notes. Each platform's release notes track capability additions; reading them periodically (every 6–12 months for platforms one cares about) keeps the mental model current.
Practitioner blogs. Daniel Tunkelang (independent), OpenSource Connections, Lucidworks, Sematext write substantial platform-related content. The Algolia, Elastic, and various search team engineering blogs publish case studies.
Conferences. Haystack Conference (relevance engineering focus), Berlin Buzzwords (open-source search and data), Activate (Lucidworks event, Solr-leaning), Elastic{ON} (Elastic's event). Conference proceedings often contain platform-comparison material that vendor blogs don't.
Benchmark studies. Independent benchmarks comparing platforms (academic papers, third-party industry benchmarks). The Vector DB Benchmarks (vector-db-benchmark on GitHub) provide useful comparison data for vector platforms.
Community discussion. Relevancy Engineering Slack, Reddit r/elasticsearch, Stack Overflow tags. Community discussion surfaces real production issues that vendor docs don't cover.
Industry analyst reports. Gartner Magic Quadrant for Insight Engines, Forrester Wave reports on search platforms. These contain biases (analyst relationships with vendors) but provide useful market-level framing for enterprise decisions.
Limits.
Few sources are unbiased. Most accessible content is platform-promotional. Triangulating across multiple sources is necessary for honest comparison.
Currency is hard to maintain. The pace of platform evolution means even good resources can be out of date quickly. Periodic re-reading of the major platforms' documentation is the only reliable way to stay current.
Best fit for.
Search practitioners making or revisiting platform decisions. Consultants advising clients on platform selection. Engineering managers needing to understand platform trade-offs without becoming specialists.
Appendix A — Platform Reference Table
Cross-reference of the platforms surveyed in this volume.
| Platform | Positioning | Best fit for | Section |
|---|---|---|---|
| Elasticsearch | General-purpose, ecosystem-rich | Mainstream production search | Section A |
| OpenSearch | Apache-licensed Elasticsearch fork | AWS-anchored deployments | Section A |
| Apache Solr | Older Lucene platform, schema-driven | Existing Solr investments | Section B |
| Vespa | Ranking-deep, ML-integrated | Recommendation, large-scale ranking | Section C |
| Algolia | SaaS, UX-rich, fast TTM | E-commerce, content search | Section D |
| Coveo | Enterprise AI-search, ML out of box | Enterprise e-commerce, support | Section E |
| Vector DBs | Specialized for embedding search | Pure-vector or RAG workloads | Section F |
| AzureAI Search | Microsoft-stack managed search | Azure-anchored, RAG with Azure OpenAI | Section G |
| Vertex AI Search | Google-stack with generative AI | GCP-anchored, generative search | Section G |
| Amazon Kendra | AWS enterprise unstructured search | Enterprise knowledge search on AWS | Section G |
| Typesense/Meili | Lightweight, dev-first, typo-focused | Small-to-medium product search | Section H |
Appendix B — The Complete Search Engineering Series
This catalog is Volume 8 of the Search Engineering Series — the final planned volume. The complete series:
- Volume 1 — The Search Patterns Catalog — query-time architectural patterns.
- Volume 2 — The Query Understanding Catalog — the methods that produce structured query signals.
- Volume 3 — The Indexing and Document Engineering Catalog — document-side preparation.
- Volume 4 — The Ranking and Relevance Catalog — scoring, LTR, neural rerankers.
- Volume 5 — The Search Evaluation Catalog — metrics, judgment, online evaluation.
- Volume 6 — The Search Operations Catalog — the day-to-day workflow.
- Volume 7 — The Search UX Patterns Catalog — the visible surfaces of the engineering.
- Volume 8 — The Search Platforms Survey (this volume) — the platforms that run all of the above.
Eight volumes, approximately 430+ pages, covering production search engineering across the disciplines, the operational practice, the user-facing surfaces, and the platform comparison. The series is structurally complete with this volume.
Appendix C — The Eight-Volume Library
With Volume 8 delivered, the Search Engineering Series is structurally complete. The library now covers production search engineering across all the disciplines, the operational practice, the user-facing surfaces, and the platforms on which all of it runs. The structural shape:
Volumes 1–5 are the technical foundation. Each volume covers one discipline — architectures, query understanding, indexing, ranking, evaluation — with patterns, methods, and code-level detail. These are the algorithmic and methodological volumes; they describe what search engineers do at the technique level.
Volume 6 is the operational integration. It uses the technical disciplines from Volumes 1–5 in the daily practice of running production search — query log analysis, regression detection, A/B testing, the cadence of weekly improvements. Operations is where the techniques meet sustained production reality.
Volume 7 is the user-facing translation. It documents the UX patterns that make the engineering visible — autocomplete, result presentation, faceted navigation, empty states, conversational interfaces. UX is where the engineering investment becomes user experience.
Volume 8 (this volume) is the platform survey. It compares the platforms on which all of the above runs, with framing for platform choice and migration. Platforms are where the technical, operational, and UX investments concentrate.
Reading the complete series. The series is too long to read end-to-end; it's designed as reference material. Different practitioners benefit from different volumes. For a search engineer joining a team: Volume 1 for vocabulary, Volume 5 for measurement discipline, Volume 6 for operational practice. For a search consultant entering a new engagement: Volume 1, Volume 5, Volume 6 plus the specific technical volumes (2, 3, 4) relevant to the engagement's focus. For a UX designer working on a search product: Volume 7 plus relevant chapters of Volume 1, 2, 4. For an engineering leader making platform decisions: Volume 8 plus relevant chapters of Volume 1, 6. The series provides reference depth across the disciplines; the reader chooses what to consume based on their role and immediate needs.
Consulting application. For consulting engagements, the complete library provides full-stack support. Engagement diagnosis uses Volume 1 framing and Volume 5 measurement. Investigation uses Volume 6 methodology. Recommendations span Volumes 2, 3, 4 depending on what surfaces. UX recommendations come from Volume 7. Platform recommendations (for clients considering platform changes) come from Volume 8. The library structure mirrors how search consulting actually works — across the disciplines, anchored in operational and platform reality, with UX as the translation layer.
The series at this point. Eight volumes, structurally complete, reflects substantial work but isn't a final state. Each volume admits revision — updated platforms (especially Volume 8), new techniques (especially in Volumes 2, 4 as LLM-integration patterns evolve), updated case studies. The current version is a draft series; future revisions will keep the material current. The skeleton of the library, however, is unlikely to change — the disciplines covered will remain the right structural framing for production search engineering for years to come.
Appendix D — Discovery and Standards
Resources for tracking the platform landscape (consolidated):
- Each platform's release notes and documentation. Reading these periodically (every 6–12 months for platforms one cares about) is the most reliable way to track capability changes.
- Practitioner blogs: Daniel Tunkelang, OpenSource Connections, Sematext. The Algolia, Elastic, Vespa engineering blogs.
- Conferences: Haystack (relevance focus), Berlin Buzzwords (open-source search), Activate (Lucidworks event), Elastic{ON} (Elastic event).
- Independent benchmarks: Vector DB Benchmarks (github.com/qdrant/vector-db-benchmark); academic papers comparing platforms; third-party industry benchmarks.
- Community discussion: Relevancy Engineering Slack, Reddit r/elasticsearch, Stack Overflow tags for each platform.
- Industry analyst reports: Gartner Magic Quadrant for Insight Engines; Forrester Wave reports on search platforms (with caveats about analyst biases).
- This series' prior volumes: Vols 1–7 establish the dimensions of comparison this volume uses.
Three practical recommendations for tracking. First, follow the release notes of the platforms your team uses or considers using. Major releases (Elasticsearch 8.x → 9.x, OpenSearch 2.x → 3.x, etc.) often add substantial capabilities. Second, attend or watch the Haystack Conference talks; the conference focuses on relevance and platform-comparison topics. Third, periodically (annually) revisit the platform landscape for your workload — the right platform today may not be the right platform in two years as platforms evolve and your workload grows.
Appendix E — Omissions
This volume covers about 11 platform entries across 8 sections — the major platforms. The wider platform landscape includes much that isn't covered here:
- Older or niche platforms: Sphinx, Xapian, Whoosh, Lucene-direct, Tantivy. Mentioned briefly; not surveyed in depth.
- Domain-specialized platforms: Lexis-Nexis/Westlaw (legal); PubMed and similar (scientific); Sourcegraph and code-search platforms; specialty enterprise platforms (Mindbreeze, Sinequa).
- Generic database full-text search: MySQL FTS, MongoDB text indexing, SQL Server full-text. Mentioned where relevant (Postgres FTS in Section F); not covered in depth elsewhere.
- Embedding model providers: OpenAI text-embedding-3, Cohere embed-v3, Voyage AI, BGE, etc. These are inputs to search platforms, not platforms themselves. Volume 4 covers their use.
- LLM orchestration frameworks: LangChain, LlamaIndex, Haystack (the framework, distinct from the conference). These sit above search platforms; covered in the agentic AI series.
- Search-quality tools that aren't platforms themselves: Quepid, RRE, OpenSource Connections' Quaerite; evaluation tooling covered in Volume 5.
- Search-as-a-service platforms targeting specific verticals: e-commerce-specialized like Bloomreach, Constructor, Klevu; workplace-specialized like Glean, Sinequa beyond what we touched on.
- Specific cloud-provider services beyond the main three: Oracle Cloud Search, IBM Watson Discovery, smaller cloud providers.
- Platforms that emerged after this draft: the platform landscape continues to evolve; new platforms launch regularly and existing platforms are acquired or pivot.
Appendix F — Final Reflections on the Series
Eight volumes of search engineering reference is more material than most search engineers will read end-to-end. The series is designed for reference — chapters and sections consumed when relevant to the practitioner's current work, not read as a continuous text. The volumes' structural completeness matters less than the patterns within them being useful when accessed.
What the series tries to be. A working library for search engineering practice. Not a textbook (textbooks exist; Manning's Introduction to Information Retrieval is free online and remains foundational). Not vendor documentation (each platform documents itself). Not a research survey (search research has its own venues). The series occupies a different niche: the patterns, methods, and structures that production search engineers use day-to-day, organized for reference rather than for linear reading. The Fowler-style pattern catalog inspired the format — each entry standalone, each pattern with the intent, motivating problem, mechanics, and applicability clearly laid out.
What the series isn't trying to be. The definitive treatment of any single topic. Each volume could be expanded substantially with more depth in specific areas; each pattern could have more code, more examples, more case studies. The series prioritizes breadth across the disciplines over depth within any single one. Specialists in any area will find the relevant volume scratches the surface of what they know; the value-add is the cross-disciplinary connection, not the single-discipline depth.
The persistence of fundamentals. Through the series, certain themes recurred. Operations matters — the discipline of running search in production is what separates teams that improve from teams that decline. Measurement matters — search work without evaluation infrastructure produces unreliable progress. UX matters — the engineering investment is invisible without it. Patterns recur — the same architectural and methodological patterns appear across different domains and platforms. These themes are likely to persist through future revisions even as specific techniques and platforms change.
The discipline's future. Search engineering through 2024–2026 has been transformed by LLM integration — query understanding, document enrichment, reranking, conversational interfaces all gained substantial new capabilities. The transformation will continue. The next several years are likely to see: further consolidation of platforms; more LLM-native search platforms; better evaluation tooling for LLM-augmented search; conversational search becoming the default rather than the exception for informational queries; vector and lexical search becoming truly unified rather than orchestrated. The principles documented in this series should remain useful, but the specific techniques and platforms will continue to evolve. Future revisions will track the evolution.
Closing. Eight volumes is enough. The series in its current form provides the reference material for production search engineering practice. Whether teams use it, consult specialists who use it, or develop their own equivalents, the field benefits from having structured reference material that's broad enough to span the disciplines and honest enough to acknowledge what works and what doesn't. This series' contribution to that goal is the draft of an eight-volume library. Revisions will follow; the structure is stable.
— End of The Search Platforms Survey (Volume 8) —
— End of the Search Engineering Series (Volumes 1–8) —